Translator programmers manual
Abstract
This document describes how to modify or create new translators for MathType for Windows 4.0 and later and/or MathType for Mac 5.0 and later. It describes the Translator Definition Language (TDL) used to specify translators and how to make new or modified translators available to MathType
Introduction
This document describes how to modify or create new translators for MathType 4.0 and later. It describes the Translator Definition Language (TDL) used to specify translators and how to make new or modified translators available to MathType It is assumed that the reader is a competent MathType user and has a good understanding of basic MathType concepts.
A small number of additional features have been added to MathType translator module since its initial release with MathType 4.0 for Windows. Such features are marked in this manual with the MathType version and platform with which the feature was introduced (e.g. MTW 5.1/MTM 5.0, which indicated MathType for Windows version 5.1 and MathType for Mac version 5.0). No new features were added for MathType 6.0 until version MathType 6.5. Features introduced in a version are available in future versions unless otherwise noted.
History
Earlier versions of MathType have had a translation facility that allows equations to be copied to the clipboard as Plain TeX, ready to be pasted into a TeX document. This facility had several limitations:
It only generated Plain TeX, whereas most users preferred LaTeX;
If the user didn't like the TeX it generated, there was nothing that could be done about it;
It could not be used to generate other mathematical languages;
There were several equation attributes (e.g. font, character style) that were ignored by the translator.
MathType 4 introduced a completely redesigned translator subsystem that removed these limitations. Its powerful features include:
Support for an unlimited number of translators, each targeting a specific language or variation of a language;
Each translator is defined by a translator definition file, a text file written in the Translator Definition Language (TDL);
The user can choose between the available translators via MathType Cut and Copy Preferences dialog;
A translator can cause an attempt to translate certain equation elements (e.g. templates) to result in an error message to the user;
MathType ships with several translators (for various kinds of TeX, MathML) that can be used as-is or modified per the user's requirements.
Using translators in MathType
First, let's examine how translators are used within MathType By default, MathType Cut and Copy commands place an equation picture on the Windows or Mac clipboard. This picture may be pasted into any document that accepts graphics from the clipboard. If the receiving application supports OLE (Microsoft's Object Linking and Embedding standard), the equation will be an embedded OLE object within the document. Alternatively, you can use MathType Cut and Copy Preferences dialog to choose a translator. From that point on, the Cut and Copy commands will invoke the translator to convert a selected part of the equation to text and/or MathML on the clipboard. The particular translator chosen will determine the language to which the equation will be translated.
The Cut and Copy Preferences dialog contains all the available translators split between two pull-down lists. These lists are built from the translator definition files found in the Translators folder (usually located in the same folder as the MathType application). Translators may be removed from the list and new ones added by moving translator definition files in and out of this folder. You can also share translators among users on a network; see MathType for Windows Administrators Manual for details.
You can create a new translator by modifying an existing translator or from scratch. Either way, you will have to understand TDL, the language used to describe translators and the subject of most of the rest of this document. It is our hope that you and other MathType users will use this information to create translators for other languages and purposes and make them available to the MathType community. See Choosing an Editing Application and Copyright and Distribution for more on these subjects.
Translator definition file structure
Translator definition files are text files whose filenames must end in ".tdl". You can edit them using a text editor (e.g. Mac's TextEdit or Windows' Notepad), a programmer's editor, or a word processor. However, if you use a word processor, you must remember to save the file in "text only" format. In the rest of this section we are going to look at the overall structure of a TDL file. You might want to open one with your favorite text editor and follow along. For our example, we'll use Bloomfire.tdl, which was introduced with MathType 6.9, but any of the TDL files will do.
The header line
The first line of the TDL file is special. Here's the first line from "Bloomfire.tdl", the translator for a website that MathType works with:
MathType Output Translator 1.0: "Bloomfire", "Bloomfire translator v1.00 by Wiris, Inc.", website, html
Let's look at this line piece-by-piece:
MathType Output Translator 1.0. This part simply serves to identify the file as a translator that translates from MathType equations to some other language; "1.0" is the version of TDL used in the file.Name:
"Bloomfire". This is the name of the translator that will be displayed in the list box in the Cut and Copy Preferences dialog. This should name the target website or application, or the language to which the translator will convert. When you want to modify an existing translator and have it appear in the translator list box along with the original one, you must make sure to give the translator a new name. If you don't, MathType will not be able to tell the two translators apart.Description:
"Bloomfire translator v1.00 by Wiris, Inc.". This is the description of the translator and will be displayed below the Cut and Copy Preferences dialog's list box when this translator is selected. This is generally a longer version of the name that should include the author and/or source of the translator and its version number.Kind:
website. Legal values for Kind arehidden,application,website, andlanguage. Targets with hidden translators will not appear in the Cut and Copy Preferences dropdown lists. Targets with application and website translators will appear in the Equation for application or website dropdown. Language targets (e.g., LaTeX) should have the value of language, and will appear in the MathML or TeX dropdown.MTW 6.7 Clip:
html. Controls what format(s) MathType puts onto the clipboard/pasteboard when this translator is used. Valid values for Clip arehtml,text, andmathml. Multiple values may be used, separated with a semicolon. Default istext.
Comments
Comments start with // and continue to the end of the line. For example.
// This is a comment.
Comments are for the human reader of a TDL file and are ignored by MathType
Clipboard behavior of MathType 6.5 and later
When translating an equation from MathType a representation of it by default gets put into the System Clipboard in two formats: text and MathML. The MathML format, given in the MathML specification http://www.w3.org/TR/MathML3/chapter6.html#world-int-transf-flavors, allows programs that are MathML-aware to know that the clipboard contains MathML as opposed to guessing that the clipboard does based on examining the first few characters. MathType Maple, MathPlayer, and Firefox are among the programs that generate and/or use this format.
The MathML format is obtained by running a default MathML translator. However, if the format output of the translator you choose to use for text is also MathML, you may want to use that translator for the MathML clipboard instead of the default one. Or you may prefer to suppress the output to MathML clipboard altogether.
To control this clipboard behavior you write one of these three possible lines in the translator file:
clipboard = text_only
to put the output of this translator on the clipboard as text and suppress output of the MathML clipboard format, or
clipboard = text_and_mathml
to put the output of this translator on the clipboard as both MathML clipboard format and text, or
clipboard = text
to put the output of this translator on the clipboard as text and use the default MathML translator for the MathML clipboard format.
The default is the text behavior.
Translation rules
Almost all the rest of a TDL file consists of translation rules. Here is an example:
root = "\sqrt #1"; // square root
This rule says that every square root template in the equation is to be translated into the string of text between double quotes. Let's take a closer look:
The word "root" is a keyword associated with this particular kind of MathType template. More about this in Templates below.
The keyword, the "=", the string enclosed in quotes, may be separated by zero or more spaces, tabs, and newlines.
The "#1" in the string will be replaced by the translation of the contents of the square root template (i.e. the stuff under the radical sign). The # is a special character in TDL called the "separator" character because it separates translation strings into parts.
This last point is most important in understanding the translation process. The rule shown in this example, along with all the others in the TDL file, will be applied recursively in a top-down order to the entire equation to be translated. The translation rules may be in any order within the TDL file - the order they will be applied is completely controlled by the contents of the equation. See Redefining Rules and Variables for more information.
Translation strings
The text string in each translation rule can be virtually unlimited in length. In order to make a long string manageable in a text editor, TDL treats adjacent strings as if they were one long string. For example, the following are equivalent:
arrow/lr/b = "\underset #1 \longleftrightarrow ";
arrow/lr/b = "\underset #1 "
"\longleftrightarrow ";
Special characters
Some characters are difficult to enter into translation strings. For example, because " is used to delimit a translation string, MathType will be confused if you just place a " in the middle of the translation string without doing something special. The escape character is used to allow characters to be entered into translation strings that would be difficult or impossible to enter otherwise. The default escape character is $. The following escape character sequences are allowed:
| means a single separator char (use # even if current sepchar is not #) |
| means a single escape char (use $ even if current escchar is not $) |
| means a single " |
| means an end-of-line (see End of Line Characters, below) |
| means a tab |
| means to increase indent (see Indenting, below) |
| means to decrease indent (see Indenting, below) |
| means a character defined by an octal value ('ooo' are octal digits) |
Both the separator and escape characters can be changed from their defaults of # and $, respectively. If one or both of these characters occur often in the target language, it may make things easier if you change them to characters that are used less frequently.
The escape character can be changed by use of the escchar command:
escchar = "^";
This will change the escape character to ^ from this point in the TDL file until the next escchar command or the end. A note of caution: if the new escape character is the current separator character, you must enter it as $#.
The separator character is used to mark special places in a translation string. The default separator is # as shown in the previous examples. This character can be changed by use of the sepchar command:
sepchar = "%";
This will change the separator character to % from this point in the TDL file until the next sepchar command or the end. A note of caution: if the new separator character is the current escape character, you must enter it as $$.
Error translations
It is very likely that not all of MathType characters and templates can be translated into the target language. In these cases, you can cause the translator to give the user an error message instead of performing a translation. Suppose the target language supports square roots, but not nth roots. To make this an error, the translation rule would look like this:
root/nth = error "Nth roots not supported; try using a fractional power.";
If this rule is invoked, the user will see this message in a dialog box. Rather than type in specific error messages for every template and character that cannot be translated, there are ways to specify a generic error message like "Unable to translate this character" (See Default Translations).
MT 6.5 You can also combine an error with a translation. This is useful where you want the translation to continue but you want the user of the translator to see that there's an issue with the output. This is done by putting both a normal translation string and the error string in the translation rule:
root/nth = "\sqrt[#2]{#1}" error "Nth root used.";
Substitution variables
There are many translation commands that allow substitution variables to appear in the translation strings. These are special names enclosed in <> that will be replaced at translation time by some text. Using the previous example once more:
root/nth = error "<Desc> not supported.";
The "<Desc>" part of the translation string will be replaced by the description of the template, resulting in an error message that says "Translation error: nth root not supported." Substitution variables can be used for both error translations and normal translations. The specific substitution variables allowed in each translation command are listed within the section of this document that describes the command.See Redefining Rules and Variables for more information.
MTW 5.0/MTM 5.0 Variables can be defined within a translator using the var command, which has the syntax:
var/"name" = "definition";
The variable name must start with a letter and be followed by zero or more letters and/or numbers. Variables, in conjunction with include files, can be used to create multiple variations on a single translator. Each translator consists of a driver file that defines the translator's header (title, etc.), followed by some variable definitions, and then one or more include commands that include TDL files common to all the set of similar translators, containing translation commands that refer to the variables defined differently in each driver file.
MTW 5.0/MTM 5.0 By default, variable references in translation strings are delimited by angle brackets (e.g. "<MyVar>"). This may not be very convenient if angle brackets are delimiters in the language which the translator is to generate. In MathML and other XML-based languages, for example, angle brackets delimit tag names. In this case, use the varchars command to change the variable delimiters at the top of your translator. For example, MathType MathML translators define the following command to change the variable delimiters to parentheses:
varchars = "()";
Include files
It is expected that many translation rules will be common to several translators. The various flavors of the TeX language, for example, have much in common and, therefore, their translators will also. TDL has an include file facility that can make it easier to maintain the common parts of a set of translator in a separate text file and have it included in each specific translator.
An include file can contain any number of lines of TDL. The filename can have any extension but we recommend that you use the .tdl extension to identify it as containing TDL. Unlike a TDL file that contains a translator, an include file must not have a header line.
To include a file in your translator, you use the include command. For example,
include "TeX Chars.tdl";
Will cause MathType to start reading TDL lines from the indicated file. When it reaches the end of that file, it will return to reading lines from the original file. Include commands may also be used in include files. However, they may be nested no more than 5 levels deep.
If the include command specifies a simple filename, as in the example, the file must be found in the same folder (directory) as the current file. Similarly for a relative pathname. However, a full pathname may be specified to cause TDL to find the file anywhere on your file system or network
Redefining rules and variables
MT 6.7 Rules and variables can be defined more than once in a TDL program. This allows more flexibility in creating multiple variations of a translator while defining most of the rules and variables in a single include file shared by all of the variations. However:
Only the last instance of each rule will be used in the translation.
The exception to this are 'run' rules, for which the first instance is used (see Translating Character Runs below for details on how run rules work.)
Variable definitions affect substitutions that follow them within the TDL program. If a variable is redefined, its new value will be used for substitutions on subsequent lines.
Because of these two points, you would want to split include files in two parts: One defining all the variables, and another with all the rules translations. That way you can redefine variables in between the two includes, and make sure that all the rules will use their new values. Your translator file modifying the base variables and rules will then look like this:
MathType Output Translator 1.0: "My Translator", "Translator from base, modified to suit my needs"
// first, include the 'base' variable definitions (can be reused in other translators)
include "Translator (base vars).tdl"
// add redefinitions of base variables immediately after including base variables file
var/"name" = "value"; // this replaces any value of the variable 'name' previously defined
... // more variable definitions
// now give your own definitions for run rules (before including the base rule file)
run/user1style = "USER1: #"; // this would replace any value of this rule that may come later
... // more run definitions
// now include the 'base' rule definitions (which may include some 'run' rules redefined above)
include "Translator (base rules).tdl"
// add redefinitions of base rules (except for 'run' rules) immediately after including base rules file
char/0x0031 = "<name>"; // replacing the rule from the 'base' rules file included above
// note that this uses the last value assigned to the variable 'name': "value"
... // more rule definitions
The translator files distributed with MathType 6.7 and later follow this pattern, so they can be used as further examples.
Pre-MT 6.7 It is an error to redefine a rule or a variable.
Equation translation
This section details the equation translation process in more detail.
MathType equation structure -- a simple example
A MathType equation is a hierarchical arrangement of building blocks such as templates and characters. Take the following familiar equation as an example:
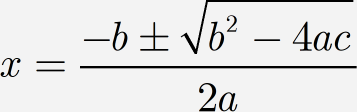
You can gain some understanding of the hierarchical structure of an equation by using the Show Nesting command on MathType View menu. Your display will look something like this:
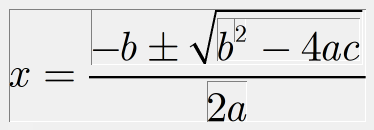
The hierarchy of this equation can be expressed in textual form as:
There are several things to note in this hierarchy:
The topmost element is always an 'equation' element. The 'equation' element can never appear anywhere else in the hierarchy.
A 'slot' element always encloses a horizontal sequence of elements, even if there is only one (as in the superscript slot in our example).
Each subelement of a template consists of a 'slot' element. The slots are numbered starting with 1 in the order that they would be visited by hitting the Tab key (although there are exceptions to this rule; see Templates below). So, for instance, the fraction template in our example contains two slots, one for the numerator and one for the denominator.
Top-level equation translation
The translation process starts with the 'equation' element. If only part of the equation is selected, translation works as if the equation consisted of an 'equation' element containing just the selection. The 'equation' element is translated using the eqn rule. Here's one for a LaTeX translator:
eqn = "\[ # \]@n";
The @ is theescape character in this translator, which means that we can use @n to produce an end-of-line in the output. The # is the separator character and will be replaced by the translation of the expression selected in the MathType window. There are also some special features of the eqn command that are described in Making Translated Equations Re-editable in MathType.
MT 6.5: If necessary, you can have an alternative translation for the top-level equation that is only used when the "Include MathType data in translation" option in the Translators dialog is checked and MathType equation data is to be included in the translation. If an eqn/eqndata command is included in the translator, and the equation data is to be embedded, they will be used to control the translation rather than the eqn command, See Making Translated Equations Re-editable in MathType for more on embedding equation data.
Inline vs display equations
If the Inline item on the Format menu is checked, the equation is an "inline" equation, meaning that it is part of a sentence or paragraph. If the Inline item is not checked, then the equation is a "display" equation and has its own paragraph. In most translators, you will want the top-level equation translation to depend on whether the equation is inline or display. You can achieve this by including two eqn commands in the translator. In the LaTeX language, for example, inline equations are surrounded by $, whereas display equations are surrounded by \[ and \]. Here are the two commands from a LaTeX translator:
eqn = "\[ # \]@n"; // '\[ <eqn> \]' -- display equation translation eqn/inline = "$#$"; // '$<eqn>$' -- inline (text) equation translation
If the equation is inline, the eqn/inline rule will be used. If the equation is display, or there is no eqn/inline rule, the eqn rule will be used.
MT 6.5: The /inline switch for eqn can be used in combination with the /eqndata one described in the previous section, yielding four possible variants for eqn translation rules: eqn, eqn/inline, eqn/eqndata and eqn/eqndata/inline.
MT 6.5: Also, in most translators, only the top-level equation translation will depend on the inline/display setting. However, you can include an inline version of virtually any translation rule. If you include a version of a rule with the /inline option, and the equation is inline according to the Inline item on the Format menu, that rule will be used for the translation instead of the normal version of the rule.
Slots
Each 'slot' element is translated with the slot command. For example,
slot = "{#}";
This will wrap the translation of the contents of the slot in braces (curly brackets). There are 16 versions of the slot command that allow you to customize the translation of slots based on the contents of the slot and where it occurs in the equation. These form 4 groups based on the position and size of the slot within the equation. Each group contains 4 variations based on the contents of the slot. Each slot command's options must appear in the order shown in the table:
Command | Conditions that determine when used |
|---|---|
Default slot translations: | |
| default |
| empty slot |
| contains only one character |
| contains only one character with embellishments |
Top-most slot (slot contained directly by the 'equation' element): | |
| default |
| empty slot |
| contains only one character |
| contains only one character with embellishments |
Slots contained directly in 'pile' elements: | |
| default |
| empty slot |
| contains only one character |
| contains only one character with embellishments |
Reduced-size slots (e.g. limits on a summation, integral, etc.): | |
| default |
| empty slot |
| contains only one character |
| contains only one character with embellishments |
For each slot, the translation string to use is determined as follows:
One of the 4 groups above is chosen based on where the slot occurs in the equation and its size. If one of the more specific groups is not chosen, the first group is used;
The content of the slot is used to choose which of the 4 variations within the group to use. If one of the more specific variations is not chosen, the first, default variation is used;
If the translation string determined by the rules above is present in the translator, it is used and we are done. Otherwise, we continue to the next step;.
If we have not tried the first, default variation in the same group, we now try it. If this translation is present, we use it. Otherwise, we continue to the next step;
If we have not tried the same variation in the first, default group, we now try it. If this translation is present, we use it. Otherwise, we continue to the next step;
If we have not tried the slot command (without any options), we now try it. If this translation is present, we use it. Otherwise, we do no translation of the slot and its contents at all.
Templates
There are many translation rules for templates, so we will not list them all here. The easiest way to find out the available template commands is to enable the display of character and template codes in MathType status bar. Do this by choosing Workspace Preferences from the Preferences menu and clicking the "Show character and template codes in status bar" checkbox. MathType will then show the template commands in parentheses after the template description when you place the mouse pointer over each template in the palettes.
Our example equation includes three templates, namely a fraction, a square root, and a superscript. The translation rules for each of these would be something like the following
frac = "\frac{#1}{#2}"; // fraction
root = "\sqrt #1"; // square root
sup = "^#2"; // superscript
A slightly more complex example is the translation rule for a summation with both an upper and lower limit:
sum = "\sum\limits_#2^#3 #1";
The #1, #2, and #3 characters get replaced by the translations of the corresponding sub-expression lines contained by the summation template. For the example, #1 is for the summand (the expression to be summed), #2 is for the lower limit, and #3 is for the upper limit. The slots are numbered starting with 1 in the order that they would be visited by hitting the Tab key right after inserting the template into an equation in a MathType window. If, however, the template is a variation of a more general template (a summation with its upper limit missing, for example), the numbering will be as if the missing item was present. You would still omit the missing items #n from its translation, though.
Template translations and the deftmpl command may contain the following substitution variables:
<Cmd>: The part of the translation command as it would appear to the left of the "=" (e.g. "union/int/b");
<Desc>: Just the textual character description; (e.g. "Union with subscript limit");
MTW 6.7: If you want to deal with determinants of matrices in your translator, there is a determinant command. It is a special case of the bar command. See Determinants for details.
Characters
Translations for characters look like this:
char/0x0078 = "x"; // Latin small letter x
char/0x00B1 = "\pm "; // plus-minus sign
These work much like template translation rules, but each character translation rule includes a hexadecimal code that is used to identify the character. For example, the hexadecimal number 0x00B1 is MathType internal code representing the plus-minus sign and is based on the Unicode standard which associates a value between 0 and 65,535 to every kind of character used in human languages in the world today. (Actually, Unicode leaves out assignments for many characters that are used in mathematics. Luckily, they have a "Private Use" range of values that MathType uses for the missing ones.) For more on Unicode, visit the Unicode Consortium website.
The easiest way to find out the Unicode values for characters is to enable the display of character and template codes in MathType status bar. Do this by choosing Workspace Preferences from the Preferences menu and clicking the "Show character and template codes in status bar" checkbox. MathType will then show the character code in parentheses after the character description when you place the mouse pointer over each symbol in the palettes. Also, the Insert Symbol dialog shows the Unicode value for the selected character.
Some target languages, such as TeX, have two "modes", text and math. It is possible for some characters to be represented in one mode differently from the other or not at all. This can be accommodated in your translator by using the "mathmode" and "textmode" options of the char command. MathType considers characters in its equations to be math or text based on the font or style associated with them. Characters are considered to be text if they are in the Text, User 1, or User 2 styles or an explicit font. Otherwise, they are considered to be math. Because MathType doesn't know how you really use the User 1 and User 2 styles, TDL has two commands that allow you to specify whether their use implies math or text:
styletype/user1 = mathmode or textmode; styletype/user2 = mathmode or textmode;
There are other ways to associate math or text mode to characters using the run command, described in a later section.
Now we have characters in math or text mode, how do you make use of this knowledge in your translator? You can specify two different translations for math and text by using the mathmode and textmode options of the char command. For example:
char/0x00B1/mathmode = "math translation"; // plus-minus sign char/0x00B1/textmode = "text translation"; // plus-minus sign
You can also specialize translation of characters having a particular font, style, or size. You do this by defining a "run" command with a name (see Font, Style, and Size Runs) and then using that name in char commands. For example, if you wanted to translate all italic numbers a special way, your translator might contain these commands:
run/italic/name/"italic run" = "#"; // don't "wrap" the run with anything
...
char/0x0030/"italic run" = "i/0"; // Digit zero
char/0x0031/"italic run" = "i/1"; // Digit one
char/0x0032/"italic run" = "i/2"; // Digit two
...
Character translations that are specialized for a particular run can also be matched by a character's font-encoded value (i.e. position within its font), instead of its Unicode value. For example, if you wanted character 0x28 in the Wingdings font (a character that looks like a telephone) to be translated to "(telephone)", you could use the following commands:
run/"Wingdings"/name/"Wingdings" = "#";
...
char/0x28/"Wingdings"/fontchar = "(telephone)";
In summary, each character is translated using these steps:
If the character is in a run and there is a char command that refers to that run, its translation is used and we are done. Otherwise, continue to the next step;
Using the style/font mechanism described above, the character's mode (math or text) is determined;
If a char command with the proper mode option is present in the translator, its translation is used and we are done. Otherwise, continue to the next step;
If a char command without a mode option is present in the translator, its translation is used and we are done. Otherwise, continue to the next step;
MTW 5.1/MTM 5.0: If the character's mode is 'math' and a defmathchar command is present in the translator, its translation is used and we are done. Otherwise, continue to the next step;
MTW 5.1/MTM 5.0: If the character's mode is 'text' and a deftextchar command is present in the translator, its translation is used and we are done. Otherwise, continue to the next step;
If a defchar command is present in the translator, its translation is used and we are done. Otherwise, no translation will be performed for the character.
The defchar command is mostly used to make untranslated characters into error messages presented to the user (see Default Translations).
Character translations and the defchar command may contain the following substitution variables:
<FullDesc>: A full description of the character including textual description, Unicode value, the font or style, position of the character in the font (e.g. "Plus-minus sign (0x00B1) from Symbol style (0xB1 from "Symbol")");
<Cmd>: The part of the translation command as it would appear to the left of the "=" (e.g. "char/0x00B1");
<Desc>: Just the textual character description (e.g. "Plus-minus sign");
<Code>: The Unicode value (e.g. "0x00B1").
<Font>: The name of the font used for the character.
<TextFont>: The name of the font assigned to the Text style.
<FunctionFont>: The name of the font assigned to the Function style.
<VariableFont>: The name of the font assigned to the Variable style.
<LCGreekFont>: The name of the font assigned to the LCGreek style.
<UCGreekFont>: The name of the font assigned to the UCGreek style.
<SymbolFont>: The name of the font assigned to the Symbol style.
<VectorFont>: The name of the font assigned to the Vector style.
<NumberFont>: The name of the font assigned to the Number style.
<User1Font>: The name of the font assigned to the User1 style.
<User2Font>: The name of the font assigned to the User2 style.
<MTExtraFont>: The name of the font assigned to the MTExtra style.
<TextFEFont>: The name of the font assigned to the TextFE style.
Character ranges MTW 5.1/MTM 5.0
Translation strings for similar characters are themselves often similar. For example, the decimal digits might be translated with rules like these:
char/0x0030 = "0"; char/0x0031 = "1"; ... char/0x0039 = "9";
In order to make translator definition files shorter and easier to read and maintain, you can have rules that specify the translation of a range of characters. The translations in the example above could be replaced by a single command:
char/0x0030/0x0039 = "<Char>";
The left side of the command specifies that it will be used when translating digits. The right side uses a substitution variable that will be replaced by the matched character. The following substitution variables may occur in a character translation string:
<Char>: The literal character. This will only work for character values less than 256 and probably won't make sense for control characters.
<CharHex>: The character value as four hex digits. Note that if you want "0x" on the front, you must supply it (e.g. "0x<CharHex>").
<CharDec>: The character value in decimal.
Subscripts, superscripts, and limits
Translation of subscripts, superscripts, and limits has some additional functionality that you might find useful. These templates differ from most other MathType templates in that they do not enclose the expression to which they apply. For example, consider the superscript template used in b2. It contains only one slot, the one containing "2". It does not contain "b". This makes translation into some target languages easy (e.g. TeX) but can cause problems for languages whose subscript, superscript, or limit constructs contain the expression to which they are applied.
You can accommodate this situation in your translator by making use of the "scan" variations of the sub, sup, subsup, and lim commands. These commands are the same as the corresponding normal template commands but have "scan" as their first option:
sup/scan sub/scan subsup/scan sup/scan/pre sub/scan/pre subsup/scan/pre lim/scan/t lim/scan lim/scan/tb
The basic idea is that these translations cause the translator to "scan" for the expression to which the template applies and then translate the template and the expression together using the "scan" translation string with the scanned expression translated as #1. These templates are translated as follows:
If the "scan" version of the translation is not present, the normal translation is used;
If the "scan" version of the translation is present, the scanning of the items surrounding the template is performed;
Scanning goes to the right for commands with the "pre" option, otherwise left;
If we are scanning right and the object next to the template is an opening "fence" character (parenthesis, bracket, brace, etc.), the slot is scanned for the corresponding closing fence character;
If we are scanning left and the object next to the template is an closing "fence" character (parenthesis, bracket, brace, etc.), the slot is scanned for the corresponding opening fence character;
If the fenced expression is found, it is used as #1 in the template translation.
If any of the above steps fail, the item next to the template in the scanning direction is used as #1 in the template translation.
MathType equation structure -- a second example
As a second example, consider the following "equation".
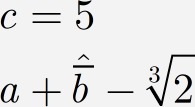
Many people would think of this as two expressions, but MathType actually thinks of it as one. The hierarchy of this second expression can be shown by:
This MathType object contains two constructs that we have not considered yet, namely piles and embellishments.
Piles
A 'pile' element encloses a vertical stack of slots produced any time you press Enter in a slot. However, if the equation consists of a single slot (like most equations), the 'equation' element would contain a single 'slot' element directly and there would be no 'pile' element.
Each 'pile' element will be translated using one of the pile commands. There are 35 versions of the pile command that allow you to customize the translation of piles based on the alignment of the pile and where it occurs in the equation. These form 5 groups based on the pile's position, size, and the number of slots it contains. Each group contains 7 variations based on how slots are aligned within the pile. Each pile command's options must appear in the order shown in the table:
Command | Conditions that determine when used |
|---|---|
Default pile translations: | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
| contains an alignment mark |
Top-most pile (pile contained directly by the 'equation' element): | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
| contains an alignment mark |
Reduced-size piles (e.g. multi-line limits on summations, integrals, etc.): | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
| contains an alignment mark |
Reduced-size piles (limits) that have exactly 2 lines: | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
| contains an alignment mark |
Reduced-size piles (limits) that have exactly 3 lines: | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
| contains an alignment mark |
For each pile, the translation string to use is determined as follows:
The most specific of the 5 groups above is chosen based on the pile's position, size, and the number of lines it contains. If one of the more specific groups is not chosen, the first group is used;
The alignment of the pile is used to choose which of the 7 variations within the group to use. If one of the more specific variations is not chosen, the first, default variation is used;
If the translation string determined by the rules above is present in the translator, it is used and we are done. Otherwise, we continue to the next step;.
If we have not tried the first, default variation in the same group, we now try it. If this translation is present, we use it. Otherwise, we continue to the next step;
If the group we tried in Steps 3 and 4 is either the lim/2 or lim/3 group, we now repeat Steps 1-4 using the appropriate group from the among first 3 groups. Otherwise, we continue to the next step;
If the group we tried in Step 5 is not the first, default group, we repeat Steps 1-4 for that group. Otherwise, we do no translation of the pile and its contents at all.
The translation strings for the first 3 groups of pile commands must have the following form:
pile = "<start>#<repeat>#<end>";
The translation of a pile using this form of translation string is performed with the following steps:
The <start> part of the translation string is output;
The first line is translated;
The <repeat> part of the translation string is output;
The next line is translated;
If there are any more lines, go back to Step 3. Otherwise, continue with the next step;
The <end> part of the translation string is output.
The translation strings for the last 2 groups of pile commands (pile/lim/2... and pile/lim/3...) must contain positional arguments; #1 for the first slot, #2 for the second, and #3 for the third (pile/lim/3... only). This kind of translation string is output with the #n's replaced by the translation of each slot in the pile, much like template translation.
Embellishments
Embellishment (accents like primes and overbars) translations work just like template translations, except their translation strings need only contain a single # as they can only contain one thing to be translated. The facts to keep in mind are:
An embellishment contains the character (or embellished character) to which it is applied;
Multiple embellishments on a single character are applied outside-in;
There will not be a pile translation wrapping the character translation.
Just as with templates, the best way to find out the embellishment commands is to use the "Show character and template codes in status bar" option in the Workspace Preferences dialog.
Embellishment translations and the defemb command may contain the following substitution variables:
<Cmd>: The part of the translation command as it would appear to the left of the "=" (e.g. "eprime/3");
<Desc>: Just the textual character description; (e.g. "Triple prime");
Matrices
Each matrix will be translated by a rather complicated process involving at least three different translation strings (more if the matrix has partition lines or the last row or the last element in each row is to be treated specially): one for the entire matrix, another that will be used once for each row in the matrix, and one that will be used for each matrix element.
There are 5 groups of matrix-related commands:
matrix, used for the entire matrix;
matrow, used for each row;
matrow/last, if present, used for the last row in the matrix;
matelem, used for each element;
matelem/last, if present, used for the last element in each row.
Within each group, there are 5 variations based on the matrix column alignment plus a default variation that is used if the variation corresponding to the alignment is not present in the translator. A simple translator that ignored column alignment and partition lines, and did not need to treat the last row or the last element in each row specially would need only define 3 commands: matrix, matrow, and matelem. The following table summarizes the matrix translation commands:
Command | Conditions that determine when used |
|---|---|
Matrix translations: | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
Matrix rows: | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
Matrix row (last in matrix): | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
Matrix elements: | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
Matrix elements (last in row): | |
| default |
| left-aligned |
| centered |
| right-aligned |
| equals-aligned (actually, any relational operator) |
| decimal point-aligned |
All of the matrix translation rules have the form:
command = "<prefix>#<suffix>";
There are partition line commands for each direction (vertical, horizontal) and each line style (solid, dashed, dotted). If the partition line commands are not given in the translator, the partition lines are ignored. Partition lines do not contain anything, so # characters are not used in their translation strings.
Horizontal partition lines | |
|---|---|
| solid |
| dashed |
| dotted |
Vertical partition lines | |
| solid |
| dashed |
| dotted |
Once the matrix, row, and element translation strings have been selected, matrix translation proceeds as follows:
The matrix prefix is output;
For all rows:
If there is a horizontal partition line above this row, it is output;
The row prefix is output;
If there is a vertical partition line to the left of the first column, it is output;
For all columns:
The element prefix is output;
The element contents are translated;
The element suffix is output;
If there is a vertical partition line to the right of this column, it is output;
The row suffix is output;
If there is a horizontal partition line below the last row, it is output;
The matrix suffix is output.
Determinants
MTW 6.7: The determinant of a square matrix is indicated by surrounding it by a vertical bar on both sides. If your translator wants to handle this case separately, you should use the determinant command. This command is a special case of the bar command and its translation has exactly the same form. The determinant command will be used in place of the the bar command if the following conditions hold for the contents of a bar template:
The bar template's slot contains only a matrix, possibly surrounded by spaces.
The matrix is square (ie, the number of rows and columns are equal).
Translating character runs
Normally, characters are translated individually using the corresponding char command. However, you might want your translator to handle a set of adjacent characters (called a "run") in a given font, style, size, etc. by translating it as a group in order to surround the character translations with some target language construct. Or, you might want to translate characters in the run in a special way.
Two kinds of character runs that are handled specially are functions (e.g. sin, cos) and numbers. The handling of functions and numbers is described below. Other kinds of runs are defined using the run command.
Functions
Functions like "sin" and "cos" are translated using func commands. Here is an example:
func/"sin" = "\sin ";
For each function in the equation, if a corresponding func command is present in the translator, it is used. Otherwise, if a deffunc command is present, it is used. The deffunc command has the form:
deffunc = "<prefix>#<suffix>
The # will be replaced by the characters of the function itself. If the deffunc is not present, the function is not translated (see Default Translations).
Function translations and the deffunc command may contain the following substitution variable:
<Func>: The character string for the function (e.g. "sin");
Numbers
Strings of consecutive digits (possibly containing a decimal point) will, by default, be handled like normal characters: each digit will be translated using the char command for that digit. However, the target language may require that numbers be enclosed in some kind of language construct. To handle this in your translator, you can use the number command:
number = "<prefix>#<suffix>
The # will be replaced by the translation of each of the characters in the number.
Font, style, and size runs
Normally, characters are translated individually using the corresponding char command. However, you might want your translator to handle a run of characters in a given font, style, size, etc. by translating it as a group in order to surround the character translations with some target language construct. Or, you might want to translate characters in the run in a special way. The run command can provide this functionality. The run command has the following form:
run/<option1>[/<option2>]... = "<prefix>#<suffix>";
where the possible options are:
/<style> where <style> is one of MathType styles (text, function, variable, greek, lc_greek, uc_greek, symbol, vector, number, extra_math, user1style, or user2style);
/<font> where <font> is a font name enclosed in double quotation marks (e.g. "Times New Roman");
/<char_style> where <char_style> is a character style (plain, bold, italic, or bold_italic);
/<pt_size> where <pt_size> is a number indicating a font's point size (must be at least 2);
/<size_name> where <size_name> is one of MathType logical sizes (full, sub, subsub, sym, subsym, user1size, or user2size);
/mathmode or /textmode (see Characters).
/name/<run_name> to associate a name with the run to be used in char commands (see Characters).
/single to indicate that the run is to be treated as a single item for the purposes of subscripts and superscripts (see Runs, Subscripts, and Superscripts).
The options can appear in any order but are subject to the following constraints:
None of the options can be given more than once;
Either the <style>, <font>, <size_name>, or <pt_size> option must be present;
The <style> and <font> options are mutually exclusive;
The <char_style> option can not be used with the <style> option;
The mathmode and text mode options are mutually exclusive;
The <pt_size> and <size_name> options are mutually exclusive;
The <run_name> must be unique for the run;
With the exception of the mathmode and textmode options, the options on a run command specify a constraint that all the characters in a "run" must satisfy. For example:
run/vector = "bold(#)";
will cause a set of consecutive characters that have the Vector-Matrix style to be enclosed by "bold()". Another example:
run/"Times New Roman"/10/italic/textmode = "special: #";
This run command matches characters that are in the "Times New Roman" font (only if the character explicitly refers to "Times New Roman"; it will not match if it is in a style that has "Times New Roman" assigned to it) and are 10 points in size and italic. The "textmode" option does not affect the matching process but overrides the math or text mode for the characters in the run, thereby affecting their translation.
The order of run commands
You may have as many run commands as you like in your translator. However, the order in which they appear is significant. Characters in a slot are processed one-at-a-time, left-to-write. For each character, all the run commands in the translator are tested against it in the order they appear. If one of them matches, it is used to match as many characters to the right of the first character that also satisfy the criteria. Generally, you should place the more specific rules first so that they will be used before the less specific ones.
Specializing character translation for a specific run
The characters contained in a run can be translated using a different set of translations from other characters. To do this, give the run a name using the name option and refer to this name in char commands. See Characters for more details.
Actually, the number and func commands are handled like run commands that match numbers and function names. You should bear in mind that these "hidden" run commands will match before any of your explicit run commands. For the purpose of specializing character translations, these runs have the names "number" and "function".
Runs, subscripts, and superscripts
Handling runs followed by a superscript or subscript require an additional attribute associated with the run command when using the "scan" versions of the sub and sup commands (see Subscripts, Superscripts, and Limits). By default, a run followed by a subscript or superscript is translated assuming that the script is applied to the last character of the run only. So, if your translator contains a run/vector command and a sup/scan command and the equation to be translated contains, say, "abc2" where "abc" is in vector style, the following translations will be made:
The run/vector command will be applied to "ab";
The sup/scan command will translated with the "c" as its operand;
The run/vector command will be applied to "c";
To suppress this behavior and treat the entire run as the operand to the sub/scan and sup/scan commands, simply add the "single" option to the run command. In the example above, the following translations will be made:
The sup/scan command will translated with the "abc" as its operand;
The run/vector command will be applied to "abc";
Functions and numbers are always handled as if they had a "single" option set so that subscript or superscript translations are applied to the entire function or number.
More translation topics
Default translations
For any target language, MathType is likely to have features (e.g. characters, templates) that cannot be translated. These can be handled simply by ignoring them, omitting commands for them from your translator. If the user of your translator attempts to translate an equation containing these items for which you have not provided a translation, they will be ignored. Depending on the target language and the particular equation, this might result in a bad translation. At a minimum, the user will mistakenly have expected the translator to have converted the MathType equation into its equivalent in the target language.
Another option is to provide error translations for those items that cannot be translated and for which you want the user to be presented with an error message (see Error Translations). An error translation is created by simply including "error" immediately after the "=" in any translation command. For example, say the target language does not provide for a plus-minus sign. You could provide an error translation for it:
char/0x00B1 = error "The plus-minus sign cannot be translated.";
The character string after "error" becomes an error message instead of a translation. This message will be displayed to the user in a "Translation Error" dialog whenever attempting to translate an equation containing a plus-minus sign.
Although you can give specific error messages for each character or template that cannot be translated, a more practical technique is to define the default translation commands (defchar, deftmpl, defemb, and deffunc) as error translations. For example,
defchar = error "The character (<FullDesc>) cannot be translated.";
This command will cause an error message to be displayed, with "<FullDesc>" replaced by a description of the character, when any character is translated for which you have not provided a translation command. The <FullDesc> variable is just one of the substitution variables that will be replaced in your error message. Here is a full list:
Char translations and the defchar command:
<FullDesc>: A full description of the character including textual description, Unicode value, the font or style, position of the character in the font (e.g. "Plus-minus sign (0x00B1) from Symbol style (0xB1 from "Symbol")");
<Cmd>: The part of the translation command as it would appear to the left of the "=" (e.g. "char/0x00B1");
<Desc>: Just the textual character description (e.g. "Plus-minus sign");
<Code>: The Unicode value (e.g. "0x00B1").
Template and embellishment translations and the deftmpl and defemb commands:
<Cmd>: The part of the translation command as it would appear to the left of the "=" (e.g. "union/int/b");
<Desc>: Just the textual character description; (e.g. "Union with subscript limit");
Function translations and the deffunc command:
<Func>: The character string for the function (e.g. "sin");
Indenting
In order to create more human-readable output from your translator, you can embed end-of-line characters in your translation strings. For example:
slot = "slot($n#$n)$n";
This command will generate output like:
slot( abc )
By using indenting, we can make the output look even better. Indenting involves two translator features, the indent command and the indenting escapes ($+, $-). MathType maintains an "indent-level" value during translation which starts at zero. Indenting escape characters can be used in your translation strings to increment ($+) or decrement ($-) the current indent-level. Whenever a newline character is placed in the translator output, it is followed by an indent-level number of copies of an indent character string. The indent-string contains the tab character by default. The indent command allows you to define the indent-string to be something other than tab; three spaces, for example:
indent = " ";
Here's how the example from above looks with indenting:
slot = "slot($+$n#$-$n)$n";
This command will generate output like:
slot( abc )
The value of indenting will become even more apparent with complicated equations.
End-of-line characters
Various computer operating systems define the end-of-line character(s) in one of several ways:
Microsoft Windows and DOS: carriage return (0x0D), line feed (0x0A);
Apple Mac: carriage return (0x0D);
UNIX: line feed (0x0A);
By default, translators will output newlines ($n) according to the particular operating system on which you are running. This is normally what you want as it allows you to create a single translator that will work on all platforms on which MathType runs. However, to change the end-of-line character sequence use the eolchars command which has the form:
eolchars = <os>;
Where <os> is either "auto" (operating system-dependent, default), "win", "mac" or "unix" to indicate one of the end-of-line character sequences as defined above.
Comment translation
Most target languages have a syntax for comments. Including comments in your translated output is easy; just include the comment in the translation string. Of course, you are responsible for making sure that the resulting comment is in accordance with the target language's syntax rules.
There are a few places in the translation process where MathType has to synthesize comments (e.g. to embed MathType equation data in the translation). To help with this task, your translator must tell MathType how to make comments in the target language with the comment command. Here is the comment command from our TeX translators:
comment = "% #";
The TeX comment syntax is that a comment starts anywhere on a line with a % and continues to the end of the line. The above translation rule will be used any time MathType must synthesize a comment, as it must when embedding equation data in the translator output. The rule says to prefix the material with "% ". Although it doesn't appear in the comment command, a newline will also be added at the end. It is your responsibility to make sure the comment command produces comments that are compatible with your target language.
Equation data converted into text that can be placed in a comment might be hundreds of characters long. Because some target languages have line-length limits and because long lines are cumbersome in a text editor, long equation data will be output as several consecutive comment lines, each no longer than 80 characters. The comment translation you provide will be used once per comment line.
Making translated equations re-editable in MathType
One powerful feature of the translators provided with MathType is the ability to paste a translated equation back into MathType for further editing. This is accomplished via a translator feature that places a text string version of MathType equation data in the translation. In the case of the TeX translators, this is done by putting the equation data into a TeX comment. This allows the equation data to be ignored by a TeX processor but when you copy the equation's translation (complete with comment) back into a MathType window, it will be recreated in its original form.
Because equation data only need appear once per translated equation, it must be included in the eqn translation string. This can be done using the EqnDataCmt and EqnData substitution variables. Both of these variables will be replaced by the empty string unless the "Include MathType data in translation" option in the Translators dialog is checked. If the option is checked, the two variables will be replaced by the equation data as follows:
The EqnDataCmt variable will be replaced by the equation data in the form of comments using the comment translation string described above;
The EqnData variable will be replaced by the equation data in the form of a single string, If your translator includes an eqndata command (which must contain a single #), it will be used to wrap the entire equation data string.
MT 6.5: If necessary, you can have an alternative translation for the top-level equation that is only used when the "Include MathType data in translation" option in the Translators dialog is checked. See Top-level Equation Translation for details.
MathType equation data is converted into a compact string of characters that is meaningless to humans. It uses 64 different characters: the upper and lower-case Roman alphabets, the digits 0-9, and two other characters (+ and -, by default). An additional character (! by default) is used to mark the beginning and end of the equation data. In order to accommodate target languages that treat any of these three characters in a special way, they can be changed using the eqndatachars command:
eqndatachars = "!+-"; // the default is shown
The character string must be exactly three characters long. The first character is the delimiter, the second and third are used with the other 62 characters to encode the equation data. If you must override the default, please choose these characters carefully.
Making translation compatible with other software
The last section was all about being able to re-edit a translated equation by selecting it in a target language document and copying it to the clipboard. This implies being able to tell where the equation to be copied starts and ends. This might not be too hard for a human operator, but is difficult for software. This section describes some translator features that can make this task easier. These features are implemented in the translators that come with MathType and are relied on by MathType support for Microsoft Word. They are also useful for allowing other software to be able to figure out where translated equations start and end.
There are two special substitution variables, StdStartCmt and StdEndCmt, that can appear in the eqn translation command. If the user checks the "Include translator name in translation" option in the Translators dialog, these variables will be expanded as follows using the comment translation:
StdStartCmt:
MathType!Translator!<translator_file>!<translator_name>!
StdEndCmt
MathType!End!
The <translator_file> and <translator_name> variables will be replaced by the name of the file used to do the translation and the translator name as it appears in the Translators dialog's translator list. The delimiter character (the ! in the above expansion is the default) may be set using the eqndatachars command.
Here's how these variables are used in a typical eqn command:
eqn = "<StdStartCmt><EqnDataCmt>#<StdEndCmt>";
This will both delimit the translated equation and embed MathType equation data in it to allow re-editing. Although you can define the eqn command to delimit translated equations any way you like, it is our hope that you will use the StdStartCmt and StdEndCmt variables in order to maximize compatibility with other software.
Equation attributes that do not translate
Most MathType equation data gets reflected in the translation if you provide rules to make use of it. However, there are a few features and attributes that are not translatable:
Nudging;
Color;
Actual positions of characters, templates, etc.;
Dimensions entered in the Define Spacing dialog on the Format menu;
Some matrix options: equal rows, equal columns, row alignment;
Fence alignment options;
Tab-stop type and position;
Although tab-stop information is not accessible in a translator, tab characters will be converted using the char/0x0009 command so some alignments can be translated.
We hope to remove some of these limitations in future versions of MathType If you have any suggestions or difficulties that you would like to see resolved in future versions, please let us know at support@wiris.com.
The development process
The development process of a new translator starts by either creating a new TDL file from scratch or by copying an existing translator. If you create a new translator from scratch, you must at least enter a valid header line before MathType will allow you to choose it in the Cut and Copy Preferences dialog. If you are modifying an existing translator, you must modify the translator name in the header in order to make it appear in one of the 2 translator lists in the Cut and Copy Preferences dialog. Once the name of your new translator appears in the dialog, you are ready to move to the next step.
The edit-compile-test cycle
In order to perform translation with your new translator, MathType must "compile" it into an internal form. Compilation occurs when you select your translator from the list and click OK. MathType will read all the lines in the TDL file and report any errors to you. If there were errors, you must correct them before MathType will allow you to use the translator to translate equations.
The bulk of the work creating a translator will consist of repeating the following steps:
Make changes and additions to your translator in your favorite text editor;
Compile it in MathType which will possibly report errors;
If there were errors, fix them and go back to Step 2;
Try your translator on some equations or expressions (start with simple ones first) by copying them to the clipboard and pasting them into a scratch text file (probably in the same text editor in which you are editing your TDL file).
If you are happy with the output of your translator, you are done. Otherwise, go back to Step 1.
Computer programmers refer to this as the edit-compile-test cycle.
Choosing an editing application
Although you can edit TDL files in a word processor, a programmer's editor is probably best for several reasons:
It allows multiple files to be open, allowing you to keep your TDL file open at the same time as a scratch file into which you can paste sample translations;
Some editing applications will make MathType report that it cannot read the file because it is open in another application, thereby forcing you to close the file after each edit;
It will properly display long lines in the translator. A word processor will generally try to wrap the lines to the right margin.
Most word processors allow you to save a document as text (rather than in its own private document format) but some will make it inconvenient by forcing you to choose a "Save as Text" option every time;
Compilation errors
If MathType detects errors in your translator, it will report them to you in a dialog that also reports the file in which the error was detected and the number of the line within the file that contains the error. While MathType does its best to get the line number right, the location reported for an error may be off by one or more lines. So, if you have trouble spotting the error on the line reported, take a look at the adjacent lines.
MathType also writes the lines to a log file so that if you have many errors, you can refer to them later by opening the log file in your text editor. On the Windows platform, the log file is written to MathType application data folder. The full path is usually:
For Windows:
C:\Users\[UserName]\AppData\Roaming\Wiris\DSMT7\MathType.log Note DSMT7 will vary, depending on the version of MathType installed.
Although we have told you that compilation takes place when you click OK in the Cut and Copy Preferences dialog after choosing a translator, there are other times at which compilation must occur (e.g. when you do the first translation in a subsequent MathType session). Errors are reported only when you compile from the Cut and Copy Preferences dialog. If errors are detected during compilation at other times, the translator will be simply unusable. For this reason, it is important that you make sure your translator is error-free using the Cut and Copy Preferences dialog before making it available for normal translation work.
Copyright and distribution
We encourage you to create new translators using the translators that come with MathType as a starting point. We do not claim any kind of copyright protection on the translators and you are free to use them as you see fit. It is our hope that you will allow other users access to your translators in order to use them and to modify them. We will be creating an area on the MathType web site (http://www.wiris.com) for exchange of translators, updates to existing translators, and as a source of translator tips and techniques. If you are considering creating a translator for a language, check our web site or contact us at support@wiris.com because someone may already have created what you need and you can avoid some work.
Happy translating!
| <a><button> Back to MathType SDK intro page</button></a> |